Managing Datasets
Working with 3D (and 2D) image datasets is at the heart of WEBKNOSSOS.
- Import datasets by uploading them directly via the web UI, streaming them from a remote server/the cloud, or by using the file system.
- Configure the dataset defaults and permissions to your specification.
- Share your datasets with the public or with selected users.
Read the section on file and data formats if you are interested in the technical background and concepts behind WEBKNOSSOS datasets.
Importing Datasets
WEBKNOSSOS supports both loading data from a local hard disk or streaming it from a remote storage server or the cloud. In either case, WEBKNOSSOS acts as the central hub to manage all your datasets in one place, search, and tag them. There are several ways to import and add a dataset to WEBKNOSSOS:
Uploading through the web browser
The easiest way to get started with working on your datasets is through the WEBKNOSSOS web interface. You can directly upload your dataset through the browser.
- From the Datasets tab in the user dashboard, click the Add Dataset button.
- Provide some metadata information:
- a name
- give access permissions for one or more teams (use the
defaultteam if all members of your organization should be able to see it) - scale of each voxel (in nanometers)
- Drag and drop your data into the upload section
- Click the Upload button
Internally, WEBKNOSSOS uses the WKW-format by default to display your data. If your data is already in WKW you can simply drag your folder (or zip archive of that folder) into the upload view.
If your data is not in WKW, you can either:
- upload the data in a supported file format and WEBKNOSSOS will automatically import or convert it (webknossos.org only).
Depending on the size of the dataset, the conversion will take some time.
You can check the progress at the
Jobspage or the "Datasets" tab in the dashboard. WEBKNOSSOS will also send you an email notification. - Convert your data manually to WKW.
In particular, the following file formats are supported for uploading (and conversion):
- WKW dataset
- OME-Zarr datasets
- Image file sequence in one folder (TIFF, JPEG, PNG, DM3, DM4)
- Multi Layer file sequence containing multiple folders with image sequences that are interpreted as separate layers
- Single-file images (OME-Tiff, TIFF, PNG, czi, raw, etc)
- Neuroglancer Precomputed datasets
- N5 datasets
Once the data is uploaded (and potentially converted), you can further configure a dataset's Settings and double-check layer properties, fine tune access rights & permissions, or set default values for rendering.
Streaming from remote servers and the cloud
WEBKNOSSOS supports loading and remotely streaming Zarr, Neuroglancer precomputed format and N5 datasets from a remote source, e.g. Cloud storage (S3) or HTTP server. WEBKNOSSOS supports loading Zarr datasets according to the OME NGFF v0.4 spec.
WEBKNOSSOS can load several remote sources and assemble them into a WEBKNOSSOS dataset with several layers, e.g. one Zarr file/source for the color layer and one Zarr file/source for a segmentation layer.
If you create the remote Zarr dataset with the WEBKNOSSOS Python library, all layers will be automatically detected.
With other converters, you may need to add the layers separately.
- From the Datasets tab in the user dashboard, click the Add Dataset button.
- Select the Add Remote Dataset tab
- For each layer, provide some metadata information:
- a URL or domain/collection identifier to locate the dataset on the remote service (supported protocols are HTTPS, Amazon S3 and Google Cloud Storage).
- authentication credentials for accessing the resources on the remote service (optional)
- Click the Add Layer button
- WEBKNOSSOS will automatically try to infer as many dataset properties (voxel size, bounding box, etc.) as possible and preview a WEBKNOSSOS
datasourceconfiguration for your to review. Consider setting the datasetnameproperty and double-check all other properties for correctness. - Click
Importto finish
WEBKNOSSOS can also import URIs from Neuroglancer. When viewing a dataset on a Neuroglancer instance in the browser, copy the URI from the address bar and paste it into the Add Remote Dataset tab to view the dataset in WEBKNOSSOS.
WEBKNOSSOS will NOT download or copy datasets in full from these third-party data providers. Rather, any data viewed in WEBKNOSSOS will be streamed read-only from the remote source. These remote datasets will not count against your storage quota on WEBKNOSSOS. Any other WEBKNOSSOS feature, e.g., annotations, and access rights, will be stored in WEBKNOSSOS and do not affect these services.
Note that data streaming may incur costs and count against any usage limits or minutes as defined by these third-party services. Check with the service provider or dataset owner.
Uploading through the Python API
For those wishing to automate dataset upload or to do it programmatically, check out the WEBKNOSSOS Python library. You can create, manage and upload datasets with the Python lib.
Uploading through the File System
-- (Self-Hosted Instances Only)--
On self-hosted instances, large datasets can be efficiently imported by placing them directly on the file system (WKW-format or Zarr only):
- Place the dataset at
<WEBKNOSSOS directory>/binaryData/<Organization name>/<Dataset name>. For example/opt/webknossos/binaryData/Springfield_University/great_dataset. - Go to the dataset view on the dashboard
- Use the
Scan disk for new datasetfrom the dropdown menu next to theRefreshbutton on the dashboard or wait for WEBKNOSSOS to detect the dataset (up to 10min)
Typically, WEBKNOSSOS can infer all the required metadata for a dataset automatically and import datasets automatically on refresh. In some cases, you will need to manually import a dataset and provide more information:
- On the dashboard, click Import for your new dataset
- Provide the requested properties, such as scale. It is also recommended to set the largestSegmentId. See the section on configuring datasets below for more detailed explanations of these parameters.
Info
If you uploaded the dataset along with a datasource-properties.json metadata file, the dataset will be imported automatically without any additional manual steps.
Using Symbolic Links
-- Self-Hosted Instances Only --
When you have direct file system access, you can also use symbolic links to import your data into WEBKNOSSOS. This might be useful when you want to create new datasets based on potentially very large raw microscopy data and symlink it to one or several segmentation layers.
Note, when using Docker, the targets of the link also need to be available to the container through mounts.
For example, you could have a link from /opt/webknossos/binaryData/sample_organization/awesome_dataset to /cluster/path/to/dataset123.
To make this dataset available to the Docker container, you need to add /cluster as another volume mount.
You can add this directly to the docker-compose.yml:
...
services:
webknossos:
...
volumes:
- ./data:/webknossos/binaryData
- /cluster:/cluster
...
Converting Datasets
Any dataset uploaded through the web interface at webknossos.org is automatically converted for compatibility.
For manual conversion, we provide the following software tools and libraries:
- The WEBKNOSSOS CLI is a CLI tool that can convert many formats to WKW.
- For other file formats, the WEBKNOSSOS Python library can be an option for custom scripting.
Composing Datasets
New datasets can also be composed from existing ones. This feature allows to combine layers from previously added datasets to create a new dataset. During compositions, transforms can optionally be defined in case the datasets are not in the same coordinate system. There are three different ways to compose a new dataset:
1) Combine datasets by selecting from existing datasets. No transforms between these datasets will be added. 2) Create landmark annotations (using the skeleton tool) for each dataset. Then, these datasets can be combined while transforming one dataset to match the other. 3) Similar to (2), two datasets can be combined while respecting landmarks that were generated with BigWarp.
See the "Compose from existing datasets" tab in the "Add Dataset" screen for more details.
Configuring Datasets
You can configure the metadata, permission, and other properties of a dataset at any time.
Note, any changes made to a dataset may influence the user experience of all users in your organization working with that dataset, e.g., removing access rights working, adding/removing layers, or setting default values for rendering the data.
To make changes, click on the "Settings" action next to a dataset in the "Datasets" tab of your dashboard. Editing these settings requires your account to have enough access rights and permissions. Read more about this.
Data Tab
The Data tab contains the settings for correctly reading the dataset as the correct data type (e.g., uint8), setting up, and configuring any layers.
Scale: The physical size of a voxel in nanometers, e.g.,11, 11, 24
For each detected layer:
Bounding Box: The position and extents of the dataset layer in voxel coordinates. The format isx, y, z, x_size,y_size, z_sizeor respectivelymin_x, min_y, min_z, (max_x - min_x), (max_y - min_y), (max_z - min_z).Largest Segment ID: The highest ID that is currently used in a segmentation layer. When a user wants to annotate a new segment and clicks "Create new Segment Id" in the toolbar, the new ID is generated by incrementing the currently known largest segment id. This value is stored per annotation and is based on the corresponding property of the underlying dataset layer. If the id is not known, the user cannot generate new segment ids. However, they can still change the currently active ID to arbitrary values. Also, they can enter a largest segment id for their annotation without having to edit the dataset's value here (which they might not have the permissions for).
The Advanced view lets you edit the underlying JSON configuration directly. Toggle between the Advanced and Simple page in the upper right. Advanced mode is only recommended for low-level access to dataset properties and users familiar with the datasource-properties.json format.
WEBKNOSSOS automatically periodically checks and detects changes to a dataset's metadata (datasource-properties.json) on disk (only relevant for self-hosted instances). Before applying these suggestions, users can preview all the new settings (as JSON) and inspect just the detected difference (as JSON).
Sharing & Permissions Tab
Make dataset publicly accessible: By default, a dataset can only be accessed by users from your organization with the correct access permissions. Turning a dataset to public will allow anyone in the general public to view the dataset when sharing a link to the dataset without the need for a WEBKNOSSOS account. Anyone can start using this dataset to create annotations. Enable this setting if you want to share a dataset in a publication, social media, or any other public website.Teams allowed to access this dataset: Defines which teams of your organization have permission to work with this dataset. By default, no team has access, but users with admin and team manager roles can see and edit the dataset.Sharing Link: A web URL pointing to this dataset for easy sharing that allows any user to view your dataset. The URL contains an access token to allow people to view the dataset without a WEBKNOSSOS account. The access token is random, and therefore the URL cannot be guessed by visitors. You may also revoke the access token to create a new one. Anyone with a URL containing a revoked token will no longer have access to this dataset. Read more in the Sharing guide.
Metadata Tab
Display Name: A meaningful name for a dataset other than its (automatically assigned) technical name which is usually limited by the naming rules of file systems. It is displayed in various parts of WEBKNOSSOS. The display name may contain special characters and can also be changed without invalidating already created sharing URLs. It can also be useful when sharing datasets with outsiders while "hiding" any internal naming schemes or making it more approachable, e.g.,L. Simpson et al.: Full Neuron Segmentationinstead ofneuron_seg_v4_2022.Description: A free-text field for providing more information about your datasets, e.g., authors, paper reference, descriptions, etc. Supports Markdown formatting. The description will be featured in the WEBKNOSSOS UI when opening a dataset in view mode.
View Configuration Tab
The View configuration tab lets you set defaults for viewing this dataset. Anytime a user opens a dataset or creates a new annotation based on this dataset, these default values will be applied.
Defaults include:
Position: Default position of the dataset in voxel coordinates. When opening the dataset, users will be located at this position.Zoom: Default zoom.Interpolation: Whether interpolation should be enabled by default.Layer Configuration: Advanced feature to control the default settings on a per-layer basis. It needs to be configured in JSON format. E.g., layer visibility & opacity, color, contrast/brightness/intensity range ("histogram sliders"), and many more.
Alternatively, these settings can be configured in a more intuitive way by opening the dataset in view mode. Change the current view settings to the desired result and save them as the dataset's default using the "Save View Configuration as Default" button in the layer settings tab.
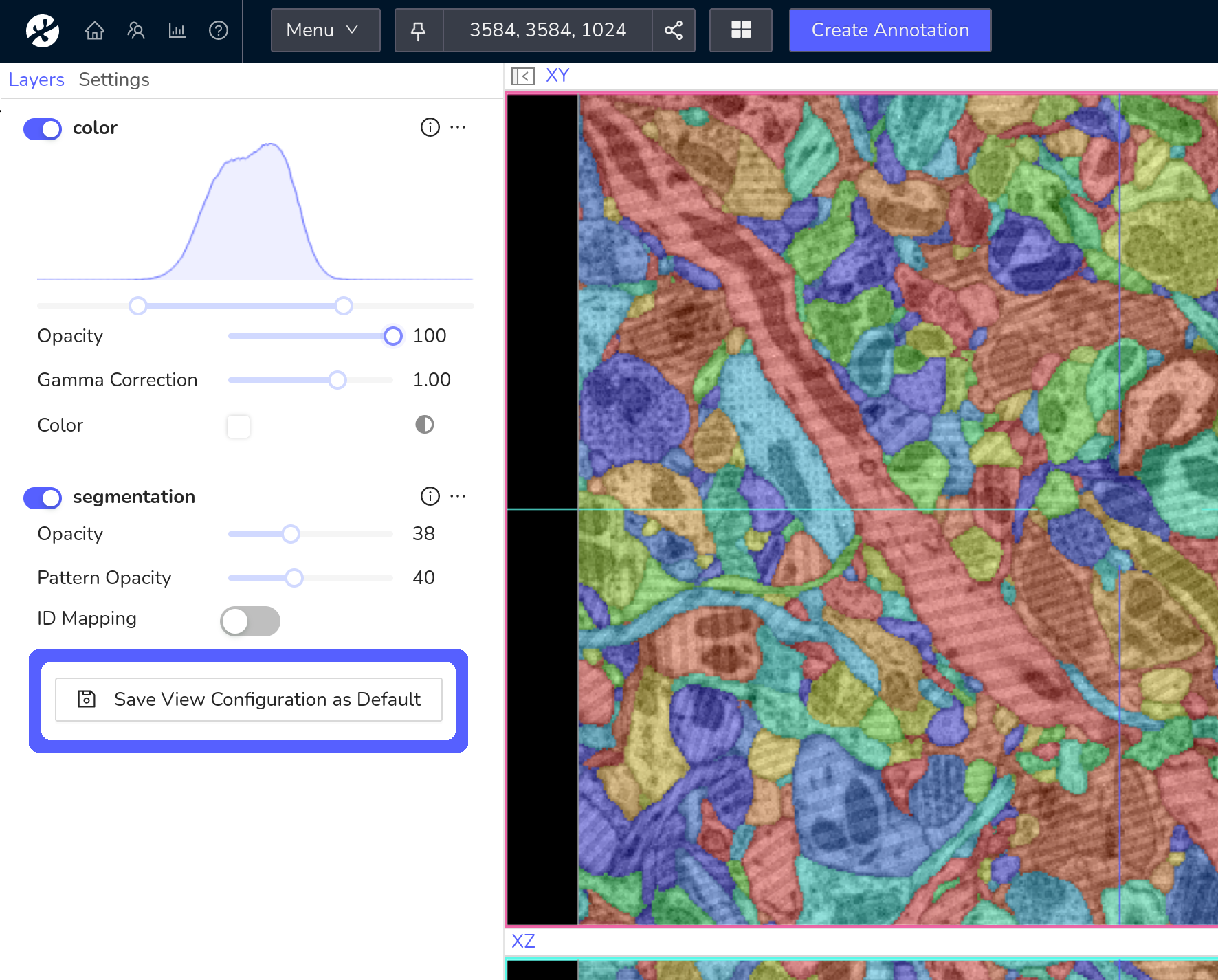
Of course, the defaults can all be overwritten and adjusted once a user opens the dataset in the main WEBKNOSSOS interface and makes changes to any of these settings in his viewports.
For self-hosted WEBKNOSSOS instances, there are three ways to set default View Configuration settings:
- in the web UI as described above
- while viewing the dataset
- inside the
datasource_properties.jsonon disk
The View Configuration from the web UI takes precedence over the datasource_properties.json.
You don't have to set complete View Configurations in either option, as WEBKNOSSOS will fill missing attributes with sensible defaults.
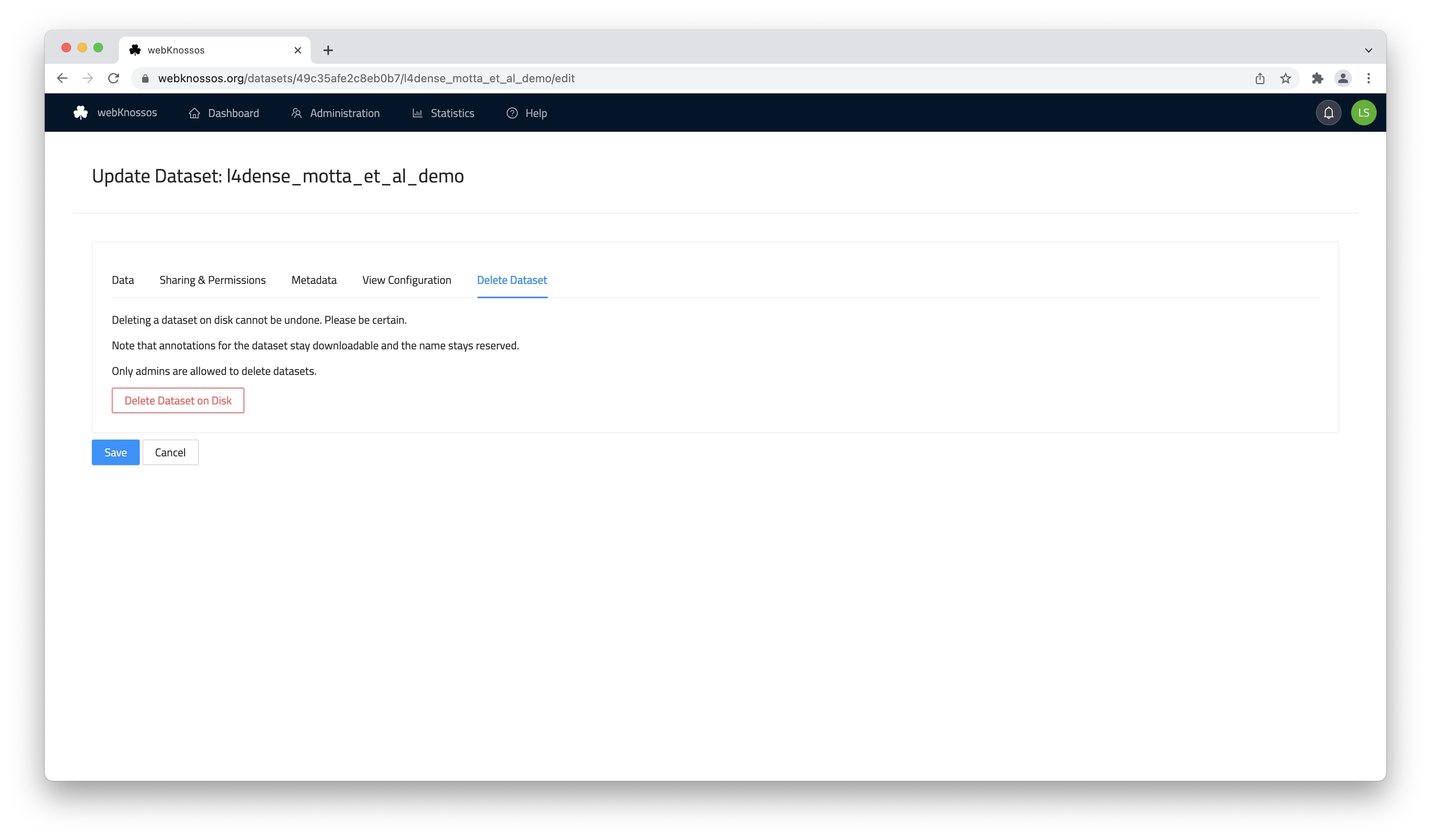
Delete Tab
Offers an option to delete a dataset and completely remove it from WEBKNOSSOS. Be careful, this cannot be undone!
Dataset Organization
In the dashboard, you can see all datasets of your organization (if you have the necessary permissions). Datasets can be organized within folders by simply dragging a dataset entry from the table to a folder in the left sidebar. New folders can be created by right-clicking an existing folder in the sidebar and selecting "New Folder".
A folder can be edited (also via the context menu) to change its name or its access permissions. In the access permissions field, a list of teams can be provided that controls which teams should have access to that folder. Note that even a folder with an empty access permissions field can be accessed by users which have access to its parent folder. This is because the access permissions are handled cumulatively.
In addition to the folder organization, datasets can also be tagged. Use the tags column to do so or select a dataset with a click and use the right sidebar.
To move multiple datasets to a folder at once, you can make use of multi-selection. As in typical file explorers, CTRL + left click adds individual datasets to the current selection. Shift + left click selects a range of datasets.
Dataset Sharing
Read more in the Sharing guide
Using External Datastores
The system architecture of WEBKNOSSOS allows for versatile deployment options where you can install a dedicated datastore server directly on your lab's cluster infrastructure. This may be useful when dealing with large datasets that should remain in your data center. Please contact us or write a post, if you require any assistance with your setup.
scalable minds also offers a dataset alignment tool called Voxelytics Align. Learn more.
Example Datasets
For convenience and testing, we provide a list of sample datasets for WEBKNOSSOS: